
UNIDAD 1
TAREA 2
CUESTIONARIO DE LA UNIDAD 1
1.- ¿Cuáles son las cuatro diferencias principales entre un sistema de procesamiento de archivos y un SGBD?
El sistema de procesamiento de archivos tiene como inconvenientes los siguientes puntos:
*Redundancia e inconsistencia de datos
*Dificultad en el acceso a los datos
*Aislamiento de datos.
*Anomalías en el acceso concurrente
Mientras que el sistema gestor de base de datos tiene las siguientes propiedades:
*Atomicidad
*Consultas de datos
*problemas de seguridad
*Problemas de integridad
2.- En este capítulo se han descrito las diferentes ventajas principales de un sistema gestor de bases de datos. ¿Cuáles son los dos inconvenientes?
1.-las bases de datos pueden ser muy grandes dependencia del tamaño de la empresa
2.-las bases de datos necesitan actualización constante
3.-Explíquese la diferencia entre independencia de datos física y lógica.
La independencia física se refiere al como se almacenan realmente los datos, es decir, las propiedades que deben tener para ser validos y almacenables, la independencia lógica se refiere a que datos son realmente almacenados en una base de datos; es decir, cuales son verdaderamente importantes para el usuario final
4.-Lístense las cinco responsabilidades del sistema gestor de la base de datos. Para cada responsabilidad explíquense los problemas que ocurrirían si no se realizara esa función
*atomicidad.- cuidar que se verifiquen los cambios en la base de datos sino se perderá información
*consistencia.- al existir se pierden los resultados esperados o cambios que se desean hacer sobre la base de datos
*transacciones.- sino existe el sistema puede guardar información errónea y se imposibilita la capacidad para hacer correcciones sobre datos desactualizados
*componente de gestión de transacciones.- al no existir se pierden los valores en caso de un fallo
*recuperación de fallos, debe detectar fallos y auto restaurar la base de datos a un estado anterior
5.- ¿Cuáles son las cinco funciones principales del administrador de la base de datos?
*Definición del esquema
*Definición de la estructura y del método de acceso.
*Modificación del esquema y de la organización física
*Concesión de autorización para el acceso a los datos
*Mantenimiento rutinario
6.- Lístense siete lenguajes de programación que sean procedimentales y dos que sean no procedimentales. ¿Qué grupo es más fácil de aprender a usar? Explíquese la respuesta.
procedimentales:
1.-cobol
2.-c
3.-c++
4.-java
5.-C#
6.-pascal
7.-delphi
no procedimentales:
ODBC
JDBC
El mas fácil de programar es el procedimental ya que se limita a tareas especificas en la base de datos mientras que los no procedimentales abarcan todas las funciones generales y la interactividad y limitaciones de los programas procedimentales
7.- Lístense los seis pasos principales que se deberían dar en la realización de una base de datos para una empresa particular.
1.-definir el costo de mantenimiento e implementación de la base de datos (costos)
2.-definir el espacio en disco duro a utilizar (almacenamiento)
3.-definir los datos que se almacenaran en la base datos (esquema)
4.-crear los programas para la gestión de la base de datos (integridad de la base de datos)
5.-imponer las reglas para las transacciones de datos (atomicidad y consistencia)
6.-tener respaldos de la base de datos (para mantenimiento)
7.-creacion de los niveles de acceso a la base de datos (seguridad y password)
8.- Considérese un array de enteros bidimensional de tamaño n × m que se va a usar en su lenguaje de programación preferido. Usando el array como ejemplo, ilústrese la diferencia (a) entre los tres niveles de abstracción y (b) entre esquema y ejemplares
Nivel físico: primero se crean los arreglos con las variables deseadas, que posteriormente serviran para hacer referencia a ellas durante el programa, posteriormente esos arreglos se deberan guardar mediante punteros en un archivo con extension txt y de nombre estudiantes
Nivel logico: se guardaran dentro de los arreglos los nombres y las matriculas de los alumnos
Nivel de vistas: el usuario normal tendra acceso a la consulta de su nombre dentro de la base de datos pero el administrador tendra la opcion para hacer la consulta, el ordenamiento por apellidos, dar de baja, altas y la modificacion de la informacion de los alumnos.
Vease la siguiente imagen que ilustra el esquema y ejemplares de la base de datos:

UNIDAD 2
ACTIVIDAD 1
2.1.- Explíquense las diferencias entre los términos clave primaria, clave candidata y súper clave.
- Clave primaria: es aquella que utilizamos para identificar una entidad de las otras de todo el conjunto de entidades.
- Clave candidata: se les llaman así a los tipos de atributos que nos permiten identificar una entidades o tipo de entidad el problema es que ese atributo puede repetirse dentro de otras entidades.
-
Super clave: es aquella que nos sirve para identificar de manera única un atributo de otros, ya sea para realizar una consulta o hacer una comparación entre otras entidades.
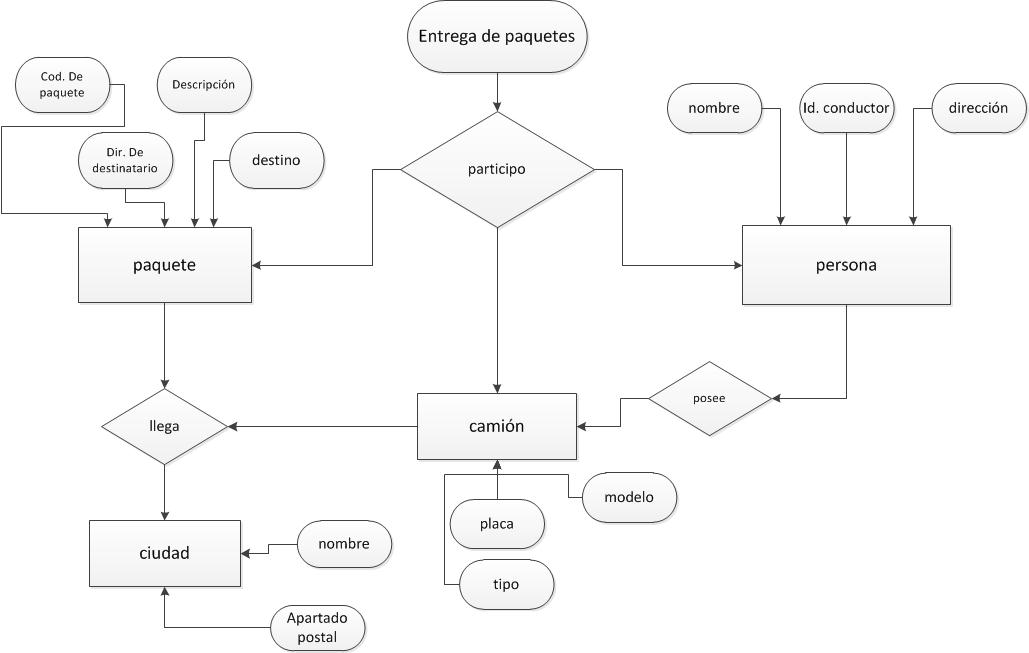
2.2.-Constrúyase un diagrama E-R para una compañía de seguros de coches cuyos clientes poseen uno o más coches. Cada coche tiene asociado un número de cero a cualquier valor que almacena el número de accidentes.

2.3. Constrúyase un diagrama E-R para un hospital con un conjunto de pacientes y un conjunto de médicos. Asóciese con cada paciente un registro de las diferentes pruebas y exámenes realizados.

2.9. Explíquense las diferencias entre conjunto de entidades
débiles y fuertes.
Las entidades débiles son aquellas que no tienen los suficientes atributos para considerárseles por una clave primaria, además de que para las entidades débiles se formaran en conjunto por otras entidades que son únicamente relacionables.
Entidades fuertes son las que por la naturaleza de sus atributos pueden tener su clave primaria; las identificamos mas fácilmente, porque es muy fácil encontrar claves candidatas pero muy difícil asignar cual de ellas será la clave primaria que nos servirá para denotar un único atributo que identifica a toda la entidad de manera simple.
2.11. Defínase el concepto de agregación. Propónganse ejemplos
para los que este concepto es útil.
Es aquella donde la relación entre los atributos de las entidades son interdependientes; es decir, que para que en un diagrama de base de datos exista una relación entre un empleado, un jefe y puesto, no existe tal relación directa sino que se utiliza una relación indirecta para expresarla en el diagrama, dicho de otro modo, para que se pueda tener un jefe se necesita un trabajador, para que un trabajador exista debe tener relación con un jefe pero ambos necesitan tener un “trabajo”, es en ese de relación que dichos atributos pueden tener una relación ternaria o cuaternaria con algún otro atributo de la base de datos.
2.12. Considérese el diagrama de la Figura 2.29, que modela una librería en línea.

a. Lístense los conjuntos de entidades y sus claves primarias.
Entidad: Cliente Clave primaria:direccion-correo-electronico
Entidad: Libro Clave primaria:ISBN
Entidad: Almacen Clave primaria:código
Entidad: Autor Clave primaria:direccion
Entidad: Editor Clave primaria:nombre
Entidad: Cesta Clave primaria: IDcesta
b. Supóngase que la librería añade casetes de música y discos compactos a su colección. El mismo elemento musical puede estar presente en formato de casete o de disco compacto con diferentes precios. Extiéndase el diagrama E-R para modelar esta adicion ignorando el efecto sobre las cestas de la compra.

c. Extiéndase ahora el diagrama E-R usando generalización para modelar el caso en que una cesta de la compra pueda contener cualquier combinación de libros, casetes de música o discos compactos.

UNIDAD 3
ACTIVIDAD 1
3.1
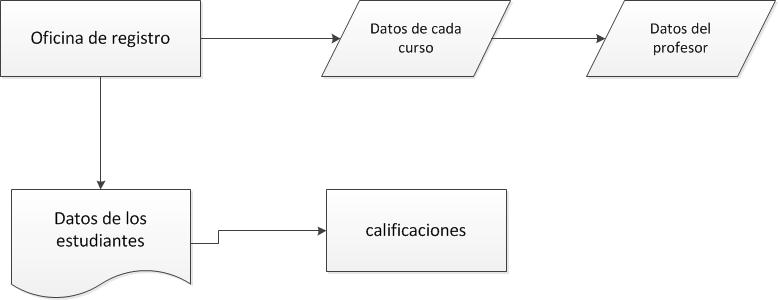
3.2: relacion y esquema de la relacion: bueno estos dos conceptos en realidad son lo mismo ya que la relacion por si sola es un conjunto de reglas, o mejor dicho de pasos que se tienen que realizar de ugual forma la de esquema de la relacion esta constituida por un conjunto o un subconjunto de pasos es asi como yo defino estos dos conceptos.
3.3
MODELOS RELACIONALES
modelos relacionales.pdf (919,3 kB)
el link de arriba de de los modelos relacionales y el ejemplo de abajo
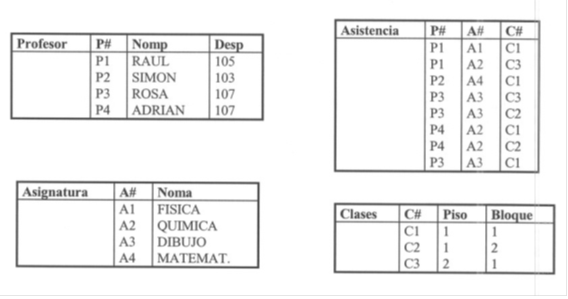
Una relación será de ahora en adelante una tabla y lo que llamábamos relación lo
llamaremos asociación.
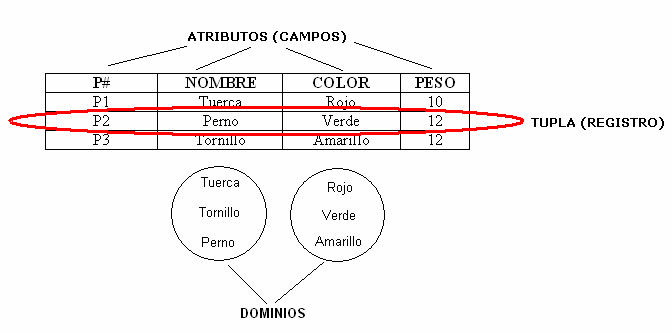
Dada una serie de conjuntos D1, D2, .., Dn (no necesariamente distintos), se dice que R es una relación sobre estos
n conjuntos si es un conjunto de n tuplas ordenadas
dn pertenece a Dn. Los conjuntos D1, D2, …, Dn son los dominios de R. El valor de n es el grado de la relación R.
TIPOS DE LLAVES
Lave primaria (SUPERLLAVE):
un campo de una tabla en el cual para todos los registros su valor es distinto puede ser una llave primaria.
Llave candidata: en una relación puede existir mas de un atributo que no contenga valores duplicados,
por lo tanto pueden ser llaves primarias (por ejemplo DODESTUDIANTE y CEDULA).
Llaves foráneas: Cuando los atributos provienen de otras relaciones.
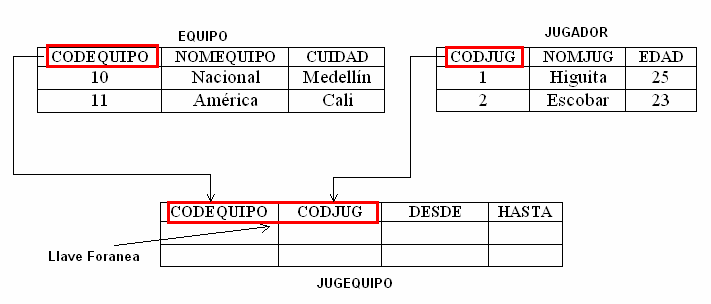
1. Relación de uno a uno:
Por cada registro de la tabla principal (tabla que contiene la clave principal) puede existir
un sólo registro en la tabla relacionada (tabla que contiene la clave externa). La tabla relacionada no puede
contener un registro que no esté relacionado con uno de la tabla principal: no puede existir un registro con
FECHA_ALTA, SALARIO, etc., si no hay un empleado con el que se relacione. Más información en uno a uno.
Esta relación se utiliza para simplicar y organizar las tablas con muchos campos. Ver el ejemplo siguiente:
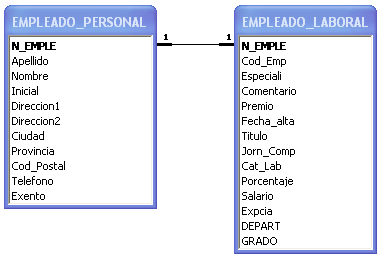
2. relación de uno a varios:
por cada registro de la tabla principal (tabla de la clave principal o lado uno de la relación)
pueden existir muchos (infinitos) registros en la tabla relacionada (tabla de la clave externa
o lado infinito de la relación). la tabla relacionada no puede contener un registro que no esté relacionado
con uno de la tabla principal, pero pueden haber muchos registro que estén relacioandos
con el mismo registro de la tabla principal: varios (infinitos) empleados de la tabla empleado_laboral,
pueden estar en el mismo departamento de la tabla departamento..
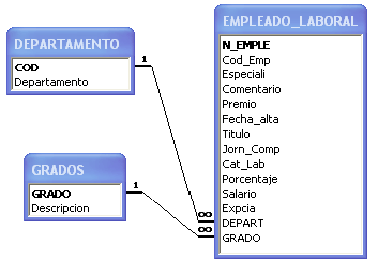
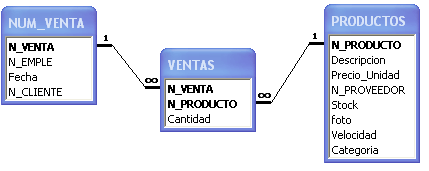
NORMALIZACION DE UNA BASE DE DATOS
A través del siguiente ejercicio se intenta afirmar los conocimientos de normalización con un ejemplo
simplificado de una base de datos para una pequeña biblioteca.
|
CodLibro |
Titulo |
Autor |
Editorial |
NombreLector |
FechaDev |
|---|---|---|---|---|---|
|
1001 |
Variable compleja |
Murray Spiegel |
McGraw Hill |
Pérez Gómez, Juan |
15/04/2005 |
|
1004 |
Visual Basic 5 |
E. Petroustsos |
Anaya |
Ríos Terán, Ana |
17/04/2005 |
|
1005 |
Estadística |
Murray Spiegel |
McGraw Hill |
Roca, René |
16/04/2005 |
|
1006 |
Oracle University |
Nancy Greenberg y Priya Nathan |
Oracle Corp. |
García Roque, Luis |
20/04/2005 |
|
1007 |
Clipper 5.01 |
Ramalho |
McGraw Hill |
Pérez Gómez, Juan |
18/04/2005 |
Esta tabla no cumple el requisito de la Primera Forma Normal (1NF) de sólo tener campos atómicos,
pues el nombre del lector es un campo que puede (y conviene) descomponerse en apellido paterno,
apellido materno y nombres. Tal como se muestra en la siguiente tabla.
1NF
|
CodLibro |
Titulo |
Autor |
Editorial |
Paterno |
Materno |
Nombres |
FechaDev |
|---|---|---|---|---|---|---|---|
|
1001 |
Variable compleja |
Murray Spiegel |
McGraw Hill |
Pérez |
Gómez |
Juan |
15/04/2005 |
|
1004 |
Visual Basic 5 |
E. Petroustsos |
Anaya |
Ríos |
Terán |
Ana |
17/04/2005 |
|
1005 |
Estadística |
Murray Spiegel |
McGraw Hill |
Roca |
|
René |
16/04/2005 |
|
1006 |
Oracle University |
Nancy Greenberg |
Oracle Corp. |
García |
Roque |
Luis |
20/04/2005 |
|
1006 |
Oracle University |
Priya Nathan |
Oracle Corp. |
García |
Roque |
Luis |
20/04/2005 |
|
1007 |
Clipper 5.01 |
Ramalho |
McGraw Hill |
Pérez |
Gómez |
Juan |
18/04/2005 |
Como se puede ver, hay cierta redundancia característica de 1NF.
La Segunda Forma Normal (2NF) pide que no existan dependencias parciales o dicho de otra manera,
todos los atributos no clave deben depender por completo de la clave primaria. Actualmente en nuestra tabla
tenemos varias dependencias parciales si consideramos como atributo clave el código del libro.
Por ejemplo, el título es completamente identificado por el código del libro, pero el nombre del lector
en realidad no tiene dependencia de este código, por tanto estos datos deben ser trasladados a otra tabla.
2NF
|
CodLibro |
Titulo |
Autor |
Editorial |
|---|---|---|---|
|
1001 |
Variable compleja |
Murray Spiegel |
McGraw Hill |
|
1004 |
Visual Basic 5 |
E. Petroustsos |
Anaya |
|
1005 |
Estadística |
Murray Spiegel |
McGraw Hill |
|
1006 |
Oracle University |
Nancy Greenberg |
Oracle Corp. |
|
1006 |
Oracle University |
Priya Nathan |
Oracle Corp. |
|
1007 |
Clipper 5.01 |
Ramalho |
McGraw Hill |
La nueva tabla sólo contendrá datos del lector.
|
CodLector |
Paterno |
Materno |
Nombres |
|---|---|---|---|
|
501 |
Pérez |
Gómez |
Juan |
|
502 |
Ríos |
Terán |
Ana |
|
503 |
Roca |
|
René |
|
504 |
García |
Roque |
Luis |
Hemos creado una tabla para contener los datos del lector y también tuvimos que crear la columna
CodLector para identificar unívocamente a cada uno. Sin embargo, esta nueva disposición de la base de datos
necesita que exista otra tabla para mantener la información de qué libros están prestados a qué lectores.
Esta tabla se muestra a continuación:
|
CodLibro |
CodLector |
FechaDev |
|---|---|---|
|
1001 |
501 |
15/04/2005 |
|
1004 |
502 |
17/04/2005 |
|
1005 |
503 |
16/04/2005 |
|
1006 |
504 |
20/04/2005 |
|
1007 |
501 |
18/04/2005 |
Para la Tercera Forma Normal (3NF) la relación debe estar en 2NF y además los atributos
no clave deben ser mutuamente independientes y dependientes por completo de la clave primaria.
También recordemos que dijimos que esto significa que las columnas en la tabla deben contener
solamente información sobre la entidad definida por la clave primaria y, por tanto,
las columnas en la tabla deben contener datos acerca de una sola cosa.
En nuestro ejemplo en 2NF, la primera tabla conserva información acerca del libro,
los autores y editoriales, por lo que debemos crear nuevas tablas para satisfacer los requisitos de 3NF.
3NF
|
CodLibro |
Titulo |
|---|---|
|
1001 |
Variable compleja |
|
1004 |
Visual Basic 5 |
|
1005 |
Estadística |
|
1006 |
Oracle University |
|
1007 |
Clipper 5.01 |
|
CodAutor |
Autor |
|---|---|
|
801 |
Murray Spiegel |
|
802 |
E. Petroustsos |
|
803 |
Nancy Greenberg |
|
804 |
Priya Nathan |
|
806 |
Ramalho |
|
CodEditorial |
Editorial |
|---|---|
|
901 |
McGraw Hill |
|
902 |
Anaya |
|
903 |
Oracle Corp. |
Aunque hemos creado nuevas tablas para que cada una tenga sólo información acerca de una entidad,
también hemos perdido la información acerca de qué autor ha escrito qué libro y las editoriales correspondientes,
por lo que debemos crear otras tablas que relacionen cada libro con sus autores y editoriales.
|
CodLibro |
codAutor |
|---|---|
|
1001 |
801 |
|
1004 |
802 |
|
1005 |
801 |
|
1006 |
803 |
|
1006 |
804 |
|
1007 |
806 |
|
CodLibro |
codEditorial |
|---|---|
|
1001 |
901 |
|
1004 |
902 |
|
1005 |
901 |
|
1006 |
903 |
|
1007 |
901 |