
Tareas d Administración de Redes UNIX
Herramientas adecuadas para el diseño y desarrollo de un sitio web
Las fases de un desarrollo web, así como los lenguajes de programación usados, son muy extensas y variadas, y por ello necesitamos herramientas específicas para cada una de ellas. Conoceremos a continuación las principales herramientas existentes para poder desarrollar fácilmente un proyecto web.
En el desarrollo web tenemos unas herramientas para el diseño, otras para la maquetación, otras para la programación, y para la depuración. Todas las herramientas que usemos son muy importantes, desde el Sistema Operativo hasta el comando más insignificante, y por ello debemos elegir la más adecuada a nuestras necesidades y capacidades.

Sistema Operativo
Para desarrollar una web, lo primero que necesitamos es un Sistema Operativo, como es lógico, y su elección no es tan trivial. Hay que tener en cuenta las aplicaciones de las que dispone el Sistema Operativo y sus costes.
Por ejemplo, tenemos Microsoft Windows, cuyas aplicaciones son muy caras, como Photoshop, Dreamweaver, Fireworks, ASP .NET… Y por otro lado tenemos GNU/Linux, con GIMP, Inkscape, Amaya, Aptana, PHP (aunque todos ellos también están disponibles en Windows).
Otra característica a tener en cuenta es las facilidades que el Sistema Operativo aporta al desarrollador, y en este sentido GNU/Linux se lleva de calle a Windows. Y esto es porque Windows no fue diseñado para los desarrolladores, sino para personas que no tienen muchos conocimientos sobre informática.
Y por el contrario GNU/Linux fue creado por desarrolladores, y para desarrolladores; y por lo tanto en GNU/Linux podemos encontrar infinidad de herramientas que nos harán la vida mucho más fácil, que además son libres.
Fases de desarrollo de una web
Para elegir las herramientas a utilizar, antes debemos identificar las fases del proceso que forman el ciclo de vida de un desarrollo web.
· Diseño: el diseño consiste en crear esbozos de la web final mediante una herramienta gráfica, como Photoshop, GIMP o Inkscape.
· Maquetación HTML/CSS: la maquetación consiste en convertir los esbozos creados en la fase anterior en plantillas HTML, su respectiva hoja de estilos, y las imágenes usadas. Es posible saltarse la fase anterior para comenzar directamente con esta fase, dependiendo de si dominamos herramientas como Photoshop o no.
· Programación cliente: la programación cliente consiste básicamente en Javascript. Una web puede no tener necesidad de hacer programación cliente, como puede ser una pequeña web corporativa con poca información estática, o puede que requiera enormes esfuerzos en esta fase, como ocurre con los proyectos Web 2.0.
· Programación servidor: en esta fase, que se desarrolla junto con la anterior, crearemos la aplicación web en un lenguaje de servidor, como puede ser PHP, ASP .NET, Python, Perl, etc.
· Depuración: esta fase enlaza la anterior con la siguiente, y es donde haremos las pruebas unitarias, aserciones, trazas, etc.
· Pruebas en local: en nuestro servidor local haremos todas las pruebas posibles.
· Subir ficheros al hosting: una vez nuestra web esté completada y bien testeada en nuestro servidor local (desarrollo), la subiremos al servidor del hosting elegido (producción). Dependiendo del hosting, podremos usar FTP, SFTP (SSH), WebDAV, o incluso Subversion. Yo aconsejo usar Subversion si así lo permite el servidor, por su comodidad y rapidez, además de por su principal utilidad, que es la de control de versiones.
· Pruebas en hosting: realizaremos las últimas pruebas en el servidor del hosting para comprobar que el cambio de servidor no ha afectado a nada. Para evitar problemas, nuestro servidor local debe tener exactamente la misma configuración que el servidor del hosting.
Herramientas: desarrollo en PHP
A continuación enumeraré las herramientas básicas para el desarrollo de una web en PHP, en sus diferentes fases de diseño e implementación.
Fases: diseño y maquetación
· Adobe Photoshop: Esta aplicación sólo está disponible en Windows, y es el más caro, aunque es el más usado y gracias a ello dispone de una gran comunidad de usuarios con los que poder contar ante cualquier problema. Con él crearemos el diseño, así como las imágenes que usemos en la maquetación.
· GIMP: Es el equivalente de software libre más próximo a Photoshop. Al ser libre es posible conseguirlo gratuitamente, y de hecho cualquier distribución GNU/Linux lo incluye. Al igual que en Photoshop, con él podremos crear el diseño y las imágenes de la maquetación HTML. También disponible en Windows
Fase: maquetación
· Inkscape: El equivalente en Windows es Adobe Fireworks. Es un excelente editor gráfico vectorial con el que poder crear iconos, banners, y demás dibujos de forma muy fácil y sencilla, incluso para aquellos que no tengan demasiados conocimientos en edición gráfica digital.
· Adobe Fireworks: El editor de gráficos vectoriales más fácil de usar que he tenido la oportunidad de usar, aunque no lo eché de menos cuando descubrí Inkscape. Al igual que su compañero Photoshop es muy caro, y más aún si tenemos una gran alternativa gratuita como es Inkscape.
Fases: maquetación, programación cliente
· Dreamweaver, Aptana, Amaya: Estas herramientas las describí en mi anterior artículo sobre los principales editores web del mercado, así que os remito a él para más información. Con ellos crearemos el código HTML/CSS (maquetación), siendo Aptana la opción más profesional para la programación cliente (Javascript).
Fase: programación servidor
· Zend Studio: Sin duda el mejor IDE existente en el mercado para desarrollo web con PHP. Es comercial, aunque no demasiado caro teniendo en cuenta la excelente herramienta que es. Además es posible descargarlo desde la web de Zend para probarlo durante 30 días.
Con él crearemos fácilmente la aplicación web en PHP. Aunque podremos usar igualmente cualquier editor. Una muy buena alternativa es Eclipse con el plugin PHP.
Otra aplicación muy útil que está muy ligada a Zend Studio es Zend Platform, un módulo para Apache que permite depurar una web directamente en el navegador (Internet Explorer o Firefox), además de otras funciones más complejas, como alertas configurables para que nos envíe un email por cada error ocurrido en la web, o cuando un script sobrepase un tiempo determinado de ejecución, por ejemplo.
Fase: prueba local
· Apache Instalar un servidor web Apache en la máquina donde desarrollamos es fundamental. De esta manera haremos pruebas rápidamente: editamos un fichero PHP, vamos al navegador, actualizamos, y vemos los cambios.
Fases: pruebas en local, depuración
· Firefox / Firebug / Web Developer Extension: Firefox es sin duda la mejor herramienta creada en los últimos tiempos para los desarrolladores web, y con Firefox sus dos extensiones más útiles para nuestra profesión: Firebug y Web Developer.
Con Firebug podremos depurar Javascript, editar HTML y CSS en la misma página para ver los cambios en tiempo real, consultar los tiempos de carga de la página en conjunto, de las imágenes, javascripts, hojas de estilo, etc, así como sus tamaños, etc. Y Web Developer nos ofrece herramientas muy útiles como ver las cookies de la web, ocultar imágenes, cambiar el tamaño del navegador a resoluciones estándar, etc.
Subir ficheros al servidor del hosting
Una vez hayamos concluido todas las fases anteriores, y nuestro proyecto esté listo, deberemos subirlo al servidor del hosting.
La herramienta a utilizar dependerá de las opciones que nos ofrezca el hosting, que desgraciadamente en la mayoría de los casos es solamente el antiguo FTP. En Dreamweaver y Zend Studio tenemos un cliente FTP y SFTP (SSH), y la tarea consistirá simplemente en configurar el FTP y copiar y pegar los directorios que queramos subir.
Confío en que esta guía sirva de ayuda a la hora de afrontar un desarrollo web. Hay que tener muy en cuenta las fases de desarrollo y usar las herramientas adecuadas: la que nos resulte más fácil de usar, la más económica, la que mejor conozcamos, etc.
FUNCION DE GET Y POST
Es aconsejable elegir “GET” para aquellas peticiones en las que se soliciten pocos datos y “POST” para aquellas en las que sea necesario enviar información, especialmente si estos datos pudieran superar los 512 bytes en total, puesto que por el método “GET” no podremos recibir la totalidad de los datos.
FUNCION DE LOS PROTOCOLOS TCP IP
Para intercambiar información entre computadores es necesario desarrollar técnicas que regulen la transmisión de paquetes. Dicho conjunto de normas se denomina protocolo. Hacia 1973 aparecieron los protocolos TCP e IP, utilizados ahora para controlar el flujo de datos en Internet.
- El protocolo TCP (y también el UDP), se encarga de fragmentar el mensaje emitido en paquetes. En el destino, se encarga de reorganizar los paquetes para formar de nuevo el mensaje, y entregarlo a la aplicación correspondiente.
- El protocolo IP en ruta los paquetes. Esto hace posible que los distintos paquetes que forman un mensaje pueden viajar por caminos diferentes hasta llegar al destino.
La unión de varias redes (ARPANET y otras) en Estados Unidos, en 1983, siguiendo el protocolo TCP/IP, puede ser considerada como el nacimiento de Internet (Interconnected Networks).
PROTOCOLO SIMPLE DE ADMINISTRACION DE RED (SNMP)
El Protocolo simple de administración de redes (SNMP) es un protocolo que permite supervisar y comunicar información de estado entre diversos hosts de una red heterogénea basada en TCP/IP.
La implementación de Windows Server 2008 de SNMP es compatible con equipos que ejecutan TCP/IPv4 y TCP/IPv6. SNMP admite el uso de IPv6 desde Windows Vista. No obstante, SNMP es compatible con IPv6 únicamente en equipos que ejecutan Windows Server 2008 o Windows Vista. Esto es debido a que SNMP requiere la pila de protocolos actualizados disponible en dichos sistemas operativos para su compatibilidad con IPv6.
Protocolo de administración de red simple (SNMP) es un sistema de administración basado en el protocolo de red. Se utiliza para administrar redes basadas en TCP/IP e IPX. Puede encontrar información sobre SNMP en la solicitud de Internet de comentarios (RFC 1157).
Microsoft proporciona un agente SNMP o cliente, para Windows NT y Windows 95. Microsoft, sin embargo, no ofrece las capacidades de administración. Hay otras compañías que ofrecen productos diseñados específicamente para la administración de SNMP. Algunos de estos productos incluyen, pero no se limitan a lo siguiente:
HP Openview (Hewlett Packard)
NMC4000 (DEVELCON)
Insight Manager de Compaq
Los productos de terceros aquí descritos están fabricados por proveedores independientes de Microsoft; no otorgamos garantía, implícita o de otro tipo, respecto al rendimiento o la confiabilidad de estos productos.
SNMP proporciona la capacidad de enviar capturas o notificaciones, para avisar a un administrador cuando una o más condiciones se cumplen. Las capturas son los paquetes de red que contienen datos relativos a un componente del sistema de envío de la captura. Los datos pueden ser estadísticos en su naturaleza o incluso estado relacionadas.
Las capturas SNMP son las alertas generadas por los agentes en un dispositivo administrado. Estas capturas generan 5 tipos de datos:
· ColdStart o reiniciar: el agente reinicializa las tablas de configuración.
· LinkUp o Linkdown: una tarjeta de interfaz de red (NIC) en el agente, se produce un error o reinicializa.
· Se produce un error de autenticación: Esto sucede cuando un agente SNMP recibe una solicitud de un nombre de comunidad no reconocido.
· egpNeighborloss: agente no puede comunicarse con su interlocutor EGP (Exterior Gateway Protocol).
· Específico de la empresa: las condiciones de error específico del proveedor y los códigos de error.
De manera predeterminada, los agentes SNMP de Microsoft no reventar nada en específico de la empresa. Esto puede cambiar, sin embargo, dependiendo de lo que está instalado en el equipo. Por ejemplo, Microsoft Systems Management Server incluye un traductor de suceso a captura que traduce los sucesos de Windows NT en capturas SNMP y las envía al host de captura.
Cómo se genera capturas
Las capturas se generan cuando se cumple una condición en el agente SNMP. Estas condiciones se definen en la Base de información de administración (MIB) proporcionado por el fabricante. A continuación, el administrador define los umbrales o limita las condiciones, que se genere una captura. Las condiciones entre los umbrales predefinidos y reiniciar el equipo. Después de que la condición se ha cumplido el agente SNMP entonces forma un paquete SNMP que especifica lo siguiente:
Versión SNMP: v1 o v2
Comunidad: Nombre de la Comunidad del agente SNMP (definido en el agente)
TIPO de PDU: Captura de SNMPvX (4)
Empresa: Corporation o la organización a la que se originó la trampa, como. 1.3.6.1.4.1. x
: Agente dirección IP del agente SNMP
Tipo genérico de captura: Inicio en frío, Link Up, empresa, etc.
Tipo específico de captura: Cuando genérico se establece a la empresa una identificación de captura específico s identificado
Marca de tiempo: El valor del objeto sysUpTime cuando se produjo el evento.
Objeto x valor x: OID de la trampa y el valor actual
Se envía el paquete anterior al host de captura SNMP o administrador, a través del puerto UDP 162.
Formato de paquete:
------------------------------------------------------
| Versión | Community | TRAP PDU |
------------------------------------------------------
Formato PDU de captura:
----------------------------------------------------------------------
| PDU TYPE | Enterprise | Agent IP | GEN trap | Spec Trap | Time Stame |
----------------------------------------------------------------------
------------------
|OBJ 1 Val 1|.....| |-Variable Bindings-|
------------------
Nota: El formato de la PDU captura anterior es todo un paquete y se ha ajustado para mejorar la legibilidad.
Cómo se generan las capturas
Todos los valores que informa de SNMP son dinámicas y no se almacenan en cualquier archivo o clave del registro. Sin embargo, la información necesaria para obtener los valores especificados se almacena en la Base de información de administración (MIB). Esta información se extiende de identificadores de objetos (OID) a unidades de datos de protocolo (PDU). Los MIB deben estar ubicados en el agente y el administrador para que funcione.
¿Dónde está toda esta información almacenada?
Manager: Software de otros fabricantes utilizado para configurar los umbrales y supervisar información SNMP.
MIB: Management Information Base. Una base de datos que define la PDU y OID.
OID: Identificador de objeto. Se trata de un identificador único que se utiliza para identificar los objetos del sistema; Por ejemplo, .1.3.6.1.4.1.311 identifica a la empresa de Microsoft.
PDU: Unidad de datos de protocolo. Las PDU son los bloques de creación de mensajes SNMP.
Host de captura: administrador responsable de supervisar las capturas SNMP.
DIAGRAMA (SNMP)
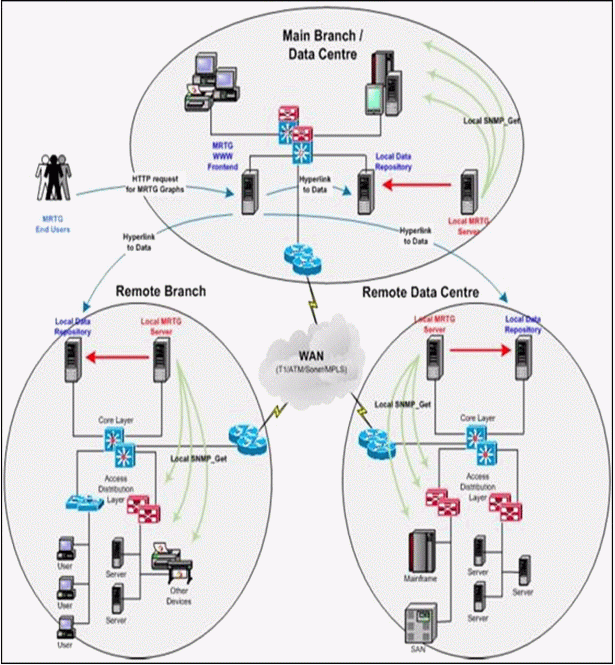
SERVICIO PARA EL SEGIMIENTOS DE SOPORTE DE RED
MRTG (Multi Router Traffic Grapher) es una herramienta, escrita en C y Perl por Tobias Oetiker y Dave Rand, que se utiliza para supervisar la carga de tráfico de interfaces de red. MRTG genera un informe en formato HTML con gráficas que proveen una representación visual de la evolución del tráfico a lo largo del tiempo.
Para recolectar la información del tráfico del dispositivo (habitualmente Reuters) la herramienta utiliza el protocolo SNMP (Simple Network Management Protocol). Este protocolo proporciona la información en crudo de la cantidad de bytes que han pasado por ellos distinguiendo entre entrada y salida. Esta cantidad bruta deberá ser tratada adecuadamente para la generación de informes
También permite ejecutar cualquier tipo de aplicación en lugar de consultar un dispositivo SNMP. Esta aplicación proporciona como salida dos valores numéricos que se corresponden a la entrada y salida. Habitualmente suelen utilizarse scripts que monitorizan la máquina local.
Asimismo, proporciona una aplicación cfgmaker que genera la configuración para un Router de forma automática utilizando la meta información que proporciona SNMP.
FUNCIONAMIENTO
MRTG ejecuta como un demonio o invocado desde las tareas programadas del cron. Por defecto, cada cinco minutos recolecta la información de los dispositivos y ejecuta los scripts que se le indican en la configuración.
En un primer momento, MRTG consultaba la información, la procesaba y generaba el informe y las gráficas. En las últimas versiones, esta información es almacenada en una base de datos gestionada por RRDtool a partir de la cual, y de forma separada, se generan los informes y las gráficas.
USOS INADECUADOS
Debido a sus características, esta herramienta ha sido utilizada de forma extensiva y adaptada para tratar información que no se adecúa a las medidas entrada/salida como proxys, procesos.
Por ello el autor de la herramienta decidió crear una segunda herramienta RRDtool más flexible que permite almacenar cualquier tipo de datos. En las últimas versiones, MRTG utiliza RRDtool quedando restringida su funcionalidad a acceder a los dispositivos configurados para alimentar al RRDtool. La gestión de los datos y la generación de las gráficas se realizan mediante RRDtool.
NTOP (de Network Top) es una herramienta que permite monitorizar en tiempo real una red. Es útil para controlar los usuarios y aplicaciones que están consumiendo recursos de red en un instante concreto y para ayudarnos a detectar malas configuraciones de algún equipo, (facilitando la tarea ya que, justo al nombre del equipo, aparece sale un banderín amarillo o rojo, dependiendo si es un error leve o grave), o a nivel de servicio.
Posee un micro servidor web desde el que cualquier usuario con acceso puede ver las estadísticas del monitorizaje.
El software está desarrollado para plataformas Unix y Windows.
En Modo Web, actúa como un servidor de Web, volcando en HTML el estado de la red. Viene con un recolector/emisor NetFlow/sFlow, una interfaz de cliente basada en HTTP para crear aplicaciones de monitoreo centradas en top, y RRD para almacenar persistentemente estadísticas de tráfico.
Los protocolos que es capaz de monitorizar son: TCP/UDP/ICMP, (R)ARP, IPX, DLC, Decnet, AppleTalk, Netbios, y ya dentro de TCP/UDP es capaz de agruparlos por FTP, HTTP, DNS, Telnet, SMTP/POP/IMAP, SNMP, NFS, X11.
DIAGRAMA NOPT
CONTROLE SUS DNS
Cloud DNS automatiza y simplifica la administración del sistema de nombres de dominio.
Acceso mediante panel de control o API
Con el Cloud Control Panel de Racks pace y la API basada en REST, puede enumerar, agregar, modificar y eliminar dominios, subdominios y registros, así como importar y exportar dominios y registros.
Migraciones sencillas
Disfrute de las migraciones sin problemas. Con un archivo de zona con formato BIND-9, fácilmente puede importar y exportar dominios y registros.
Tiempo de funcionamiento confiable
Nuestra infraestructura de DNS emplea enrutamiento Anycast IP, una de las mejores prácticas de la industria, que ofrece a nuestros servidores el mejor tiempo de funcionamiento posible en todo el mundo.
¡La mejor parte es que no tiene costo!
Así es, ¡usar Cloud DNS de Rackspace no tiene costo! Los clientes de Cloud Sites, RackConnect® y Cloud Servers tienen acceso automático a Cloud DNS, por defecto.
LDAP son las siglas de Lightweight Directory Access Protocol (en español Protocolo Ligero de Acceso a Directorios) que hacen referencia a un protocolo a nivel de aplicación que permite el acceso a un servicio de directorio ordenado y distribuido para buscar diversa información en un entorno de red. LDAP también se considera una base de datos (aunque su sistema de almacenamiento puede ser diferente) a la que pueden realizarse consultas.
Un directorio es un conjunto de objetos con atributos organizados en una manera lógica y jerárquica. El ejemplo más común es el directorio telefónico, que consiste en una serie de nombres (personas u organizaciones) que están ordenados alfabéticamente, con cada nombre teniendo una dirección y un número de teléfono adjuntos. Para entender mejor, es un libro o carpeta, en la cual se escriben nombres de personas, teléfonos y direcciones, y se ordena alfabéticamente.
Un árbol de directorio LDAP a veces refleja varios límites políticos, geográficos u organizacionales, dependiendo del modelo elegido. Los despliegues actuales de LDAP tienden a usar nombres de Sistema de Nombres de Dominio (DNS por sus siglas en inglés) para estructurar los niveles más altos de la jerarquía. Conforme se desciende en el directorio pueden aparecer entradas que representan personas, unidades organizacionales, impresoras, documentos, grupos de personas o cualquier cosa que representa una entrada dada en el árbol (o múltiples entradas).
Habitualmente, almacena la información de autenticación (usuario y contraseña) y es utilizado para autenticarse aunque es posible almacenar otra información (datos de contacto del usuario, ubicación de diversos recursos de la red, permisos, certificados, etc.). A manera de síntesis, LDAP es un protocolo de acceso unificado a un conjunto de información sobre una red.
GESTIÓN DE ARCHIVOS
El principal objetivo de un sistema de archivos distribuido es la integración transparente de los archivos de un sistema distribuido, permitiendo, compartir datos a los usuarios del mismo. En un sistema de archivos distribuido, cada archivo se almacena en un único servidor. Existen otros tipos de sistemas, como son los sistemas de archivos distribuidos con acceso paralelo y los sistemas de archivos paralelos qué distribuyen los datos de un mismo archivo entre diferentes servidores. El objetivo de éstos es mejorar el rendimiento en el acceso a los datos.
Un sistema de archivos distribuido se construye normalmente siguiendo una arquitectura cliente-servidor, con los módulos clientes ofreciendo la interfaz de acceso a los datos y los servidores encargándose del nombrado y acceso a los archivos. El modelo anterior consta, normalmente, de dos componentes claramente diferenciados:
• El servicio de directorio, que se encarga de la gestión de los nombres de los archivos. El objetivo es ofrecer un espacio de nombres único en el sistema con total transparencia de acceso a los archivos. Los nombres de los archivos no deberían hacer alusión al servidor en el que se encuentran almacenados.
• El servicio de archivos, que proporciona acceso a los datos de los archivos.
Métodos de acceso remotos
Existen tres modelos de acceso en un sistema de archivos distribuido.
• Modelo carga/descarga. En este modelo, cada vez que un cliente desea acceder a un archivo se transfiere en su totalidad del servidor al cliente. Una vez en el cliente, los procesos de usuario acceden al archivo como si se almacenará de forma local. Este modelo ofrece un gran rendimiento en el acceso a los datos, ya que éstos se acceden de forma local. Sin embargo, puede llevar a un modelo en el que un mismo archivo resida en múltiples clientes a la vez, lo que presenta problemas de coherencia.
• Modelo de servicios remotos. En este caso,: el servidor ofrece todos los servicios relacionados con el acceso a los archivos. Todas las operaciones de acceso a los archivos se resuelven mediante peticiones a los servidores, siguiendo un modelo cliente-servidor. Normalmente, el acceso en este tipo de modelos se realiza en bloques. El gran problema de este esquema es el rendimiento, ya que todos los accesos a los datos deben realizarse a través de la red.
• Empleo de cache. Este modelo combina los dos anteriores. Los clientes del sistema de archivos disponen de una cache, que utilizan .para almacenar los bloques más recientemente accedidos. Cada vez que un proceso accede a un bloque, el cliente busca en la cache local. En caso de que se encuentre, el acceso se realiza sin necesidad de contactar con el servidor.
(NFS)
El Network File System (Sistema de archivos de red), o NFS, es un protocolo de nivel de aplicación, según el Modelo OSI. Es utilizado para sistemas de archivos distribuido en un entorno de red de computadoras de área local. Posibilita que distintos sistemas conectados a una misma red accedan a ficheros remotos como si se tratara de locales. Originalmente fue desarrollado en 1984 por Sun Microsystems, con el objetivo de que sea independiente de la máquina, el sistema operativo y el protocolo de transporte, esto fue posible gracias a que está implementado sobre los protocolos XDR (presentación) y ONC RPC (sesión).1 El protocolo NFS está incluido por defecto en los Sistemas Operativos UNIX y la mayoría de distribuciones Linux.
Características
· El sistema NFS está dividido al menos en dos partes principales: un servidor y uno o más clientes. Los clientes acceden de forma remota a los datos que se encuentran almacenados en el servidor.
· Las estaciones de trabajo locales utilizan menos espacio de disco debido a que los datos se encuentran centralizados en un único lugar pero pueden ser accedidos y modificados por varios usuarios, de tal forma que no es necesario replicar la información.
· Los usuarios no necesitan disponer de un directorio “home” en cada una de las máquinas de la organización. Los directorios “home” pueden crearse en el servidor de NFS para posteriormente poder acceder a ellos desde cualquier máquina a través de la infraestructura de red.
· También se pueden compartir a través de la red dispositivos de almacenamiento como disqueteras, CD-ROM y unidades ZIP. Esto puede reducir la inversión en dichos dispositivos y mejorar el aprovechamiento del hardware existente en la organización.
Todas las operaciones sobre ficheros son síncronas. Esto significa que la operación sólo retorna cuando el servidor ha completado todo el trabajo asociado para esa operación. En caso de una solicitud de escritura, el servidor escribirá físicamente los datos en el disco, y si es necesario, actualizará la estructura de directorios, antes de devolver una respuesta al cliente. Esto garantiza la integridad de los ficheros.
(SMD)
La tecnología de montaje superficial, más conocida por sus siglas en inglés SMT (Surface Mount Technology) es el método de construcción de dispositivos electrónicos más utilizado actualmente. Se usa tanto para componentes activos como pasivos, y se basa en el montaje de los mismos (SMC, en inglés Surface Mount Component) sobre la superficie del circuito impreso. Tanto los equipos así construidos como los componentes de montaje superficial pueden ser llamados dispositivos de montaje superficial, o por sus siglas en inglés, SMD (Surface Mount Device).
Mientras que los componentes de tecnología through hole atraviesan la placa de circuito impreso de un lado a otro, los análogos SMD, que son muchas veces más pequeños, no la atraviesan: las conexiones se realizan mediante contactos planos, una matriz de esferas en la parte inferior del encapsulado, o terminaciones metálicas en los bordes del componente.
Este tipo de tecnología ha superado y remplazado ampliamente a la through hole en aplicaciones de producción masiva (por encima de las miles de unidades), de bajo consumo de energía (como dispositivos portátiles), de baja temperatura y/o de multiaplicaciones en tamaño reducido (como equipo de cómputo, medición e instrumentación). Sin embargo, debido a su reducido tamaño, el ensamblado manual de las piezas se dificulta, por lo que se necesita mayor automatización en las líneas de producción, y también se requiere la implementación de técnicas más avanzadas de diseño para que los SMD funcionen adecuadamente aún en ambientes con altos índices de EMI.
La tecnología de montaje superficial fue desarrollada por los años '60 y se volvió ampliamente utilizada a fines de los '80. La labor principal en el desarrollo de esta tecnología fue gracias a IBM y Siemens. La estructura de los componentes fue rediseñada para que tuvieran pequeños contactos metálicos que permitiese el montaje directo sobre la superficie del circuito impreso. De esta manera, los componentes se volvieron mucho más pequeños y la integración en ambas caras de una placa se volvió algo más común que con componentes through hole. Usualmente, los componentes sólo están asegurados a la placa a través de las soldaduras en los contactos, aunque es común que tengan también una pequeña gota de adhesivo en la parte inferior. Es por esto, que los componentes SMD se construyen pequeños y livianos. Esta tecnología permite altos grados de automatización, reduciendo costos e incrementando la producción. Los componentes SMD pueden tener entre un cuarto y una décima del peso, y costar entre un cuarto y la mitad que los componentes through hole.
Hoy en día la tecnología SMD es ampliamente utilizada en la industria electrónica, esto es debido al incremento de tecnologías que permiten reducir cada día más el tamaño y peso de los componentes electrónicos. La evolución del mercado y la inclinación de los consumidores hacia productos de menor tamaño y peso, hizo que este tipo de industria creciera y se expandiera; hoy en día componentes tan pequeños en su dimensión como 0.5 milímetros son montados por medio de este tipo de tecnología. En la actualidad casi todos los equipos electrónicos de última generación están constituidos por este tipo de tecnología. LCD TV's, DVD, reproductores portátiles, teléfonos móviles, laptop's, por mencionar algunos.
DOMINIOS DE RED
Un localizador de recursos uniforme, más comúnmente denominado URL (siglas en inglés de uniform resource locator), es una secuencia de caracteres, de acuerdo a un formato modélico y estándar, que se usa para nombrar recursos en Internet para su localización o identificación, como por ejemplo documentos textuales, imágenes, vídeos, presentaciones digitales, etc. Los localizadores uniformes de recursos fueron una innovación en la historia de la Internet. Fueron usadas por primera vez por Tim Berners-Lee en 1991, para permitir a los autores de documentos establecer hiperenlaces en la World Wide Web. Desde 1994, en los estándares de la Internet, el concepto de URL ha sido incorporado dentro del más general de URI (Uniform Resource Identifier, en español identificador uniforme de recurso), pero el término URL aún se utiliza ampliamente.
Aunque nunca fueron mencionadas como tal en ningún estándar, mucha gente cree que las iniciales URL significan universal -en lugar de 'uniform'- resource locator (localizador universal de recursos). Esta se debe a que en 1990 era así, pero al unirse las normas "Functional Recommendations for Internet Resource Locators" [RFC1736] y "Functional Requirements for Uniform Resource Names" [RFC1737] pasó a denominarse Identificador Uniforme de Recursos [RFC 2396]. Sin embargo, la U en URL siempre ha significado "uniforme".
El URL es una cadena de caracteres con la cual se asigna una dirección única a cada uno de los recursos de información disponibles en la Internet. Existe un URL único para cada página de cada uno de los documentos de la World Wide Web, para todos los elementos de Gopher y todos los grupos de debate USENET, y así sucesivamente.
El URL de un recurso de información es su dirección en Internet, la cual permite que el navegador la encuentre y la muestre de forma adecuada. Por ello el URL combina el nombre del ordenador que proporciona la información, el directorio donde se encuentra, el nombre del archivo, y el protocolo a usar para recuperar los datos para que no se pierda alguna información sobre dicho factor que se emplea para el trabajo.
IPER ENLACE
Un hipervínculo (también llamado enlace, vínculo, o hiperenlace) es un elemento de un documento electrónico que hace referencia a otro recurso, por ejemplo, otro documento o un punto específico del mismo o de otro documento. Combinado con una red de datos y un protocolo de acceso, un hipervínculo permite acceder al recurso referenciado en diferentes formas, como visitarlo con un agente de navegación, mostrarlo como parte del documento referenciador o guardarlo localmente.
Los hipervínculos son parte fundamental de la arquitectura de la World Wide Web, pero el concepto no se limita al HTML o a la Web. Casi cualquier medio electrónico puede emplear alguna forma de hiperenlace.
GTLD
Un dominio de nivel superior genérico (generic Top Level Domain o gTLD) es una de las categorías de dominios de nivel superior que mantiene la Internet Assigned Numbers Authority (IANA) para su uso en el sistema de nombres de dominio de Internet. Es visible para los usuarios de Internet como el sufijo al final de un nombre de dominio (ej: .com).
En general, IANA actualmente distingue los siguientes grupos de dominios de nivel superior:
· Dominios de nivel superior de infraestructura (.arpa)
· Dominios de nivel superior geográficos (ccTLD)
· Dominios de nivel superior genéricos (gTLD)
· Dominios de nivel superior internacionalizados (con caracteres distintos del alfabeto latino)
Los dominios de nivel superior genéricos (gTLD) están formados por un mínimo de 3 letras, para diferenciarlos de los dominios geográficos (ccTLD), que consisten en códigos de dos letras asignados a cada país o territorio. Los dominios genéricos se asignan de acuerdo al destino o propósito para el que han sido creados.
CcTLD
Un dominio de nivel superior geográfico o dominio de nivel superior de código de país (en inglés: country code top-level domain o ccTLD) es un dominio de Internet usado y reservado para un país o territorio dependiente.
Los ccTLD (véase la lista del IANA) tienen una longitud de dos caracteres, y la mayoría corresponden al estándar de códigos de países ISO 3166-1 (las diferencias se explican más adelante). Cada país designa gestores para su ccTLD y establece las reglas para conceder dominios. Algunos países permiten que cualquier persona o empresa del mundo adquiera un dominio dentro de sus ccTLD, por ejemplo Austria (.at) o España (.es). Otros países solo permiten a sus residentes adquirir un dominio de su ccTLD, por ejemplo Australia (.au), Andorra (.ad) y Chile (.cl).